5주차 정리
Node.Js 섹션 1~2.5
섹션 0.HTTP
1. Javascript와 HTTP
http = Hypertext Transfer Protocol
- 팀 버너스 리(tim berners-lee)라고 하는 웹의 창시자에 의해 만들어짐
- 웹 브라우저와 웹 서버 사이에서 서로 주거니 받거니 하기 위해서 나름대로의 규칙이 필요하다. 그 규칙을 정의하기 위해 만든 통신 방법이 바로 http이다.
- 웹브라우저의 주소창에 어떤 주소를 입력하고 엔터를 치면, 웹브라우저는 웹서버를 찾아가서 어떤 정보를 요청하는 데 이것을 영어로 Request(요청)라고 한다.
- 그럼 웹서버는 그 요청에 따라서 적당한 정보를 웹브라우저에게 응답하고 바로 그것을 영어로 Response(응답)라고 부른다

- 요청과 응답은 사실 컴퓨터와 컴퓨터 사이의 일이기 때문에, 그 안에는 엄격한 규칙들이 존재한다. 그 규칙은 문자로 되어 있는 단순한 어떤 메시지를 웹브라우저와 웹서버가 주고받는 것이다.
- 크롬에서 오른쪽 마우스를 클릭하면 검사(inspect)라는 게 있다. 이걸 클릭하면 나오는 창에서 Network라는 탭을 클릭한다.

- 이건 웹브라우저와 웹서버가 서로 데이터를 주고 받는 모습을 보여주는 도구이다. 여기 'expressjs.com'이라는 주소로 엔터를 쳐서 접속을 하면 엄청나게 많은 파일들을 다운 받는 걸 볼 수 있다.

- 여기서 제일 위에 있는 'expressjs.com'이 html 파일이다. 클릭하면 이 html 정보를 웹브라우저가 요청하고 웹서버가 응답하는 과정을 자세히 볼 수 있다.
[Request Headers]

- Request Headers라고 되어있는 이 부분이 웹브라우저가 웹서버에게 요청할 때 작성한 요청서이다. 웹브라우저는 응답헤더에 적혀있는 내용을 참고로 해서 여러 가지 작업들을 처리하게 된다.
- User-Agent라고 되어 있는 부분은 웹브라우저이다. 즉, 요청을 할 때 어떤 웹브라우저로 요청을 했는지에 대한 정보가 넘어간다. 그럼 웹서버는 저 정보를 받아서 어떤 브라우저들이 지금 접속하고 있는지를 파악할 수 있다.
- Accept-Language라고 되어있는 부분에는 이 웹브라우저가 수용할 수 있는, 처리할 수 있는 언어들이 적혀 있다.
- Accept-Encoding : 웹브라우저와 웹서버가 서로 데이터를 주고 받을 때 이 웹서버에서 데이터를 응답하는데, 그 내용이 너무 크면 부담스럽다. 그런 경우에는 이런 gzip방식으로 웹서버가 압축을 해서 웹브라우저에게 주게 된다. 그런데 웹브라우저가 그 압축을 풀 수 있는 능력이 없으면 안 된다. 그러니까 '웹브라우저가 압축을 해제할 수 있다'라는 정보를 웹서버에게 보내주면 웹서버는 저걸 보고 압축해서 보낼지 말지를 결정하게 된다.
[Response Headers]
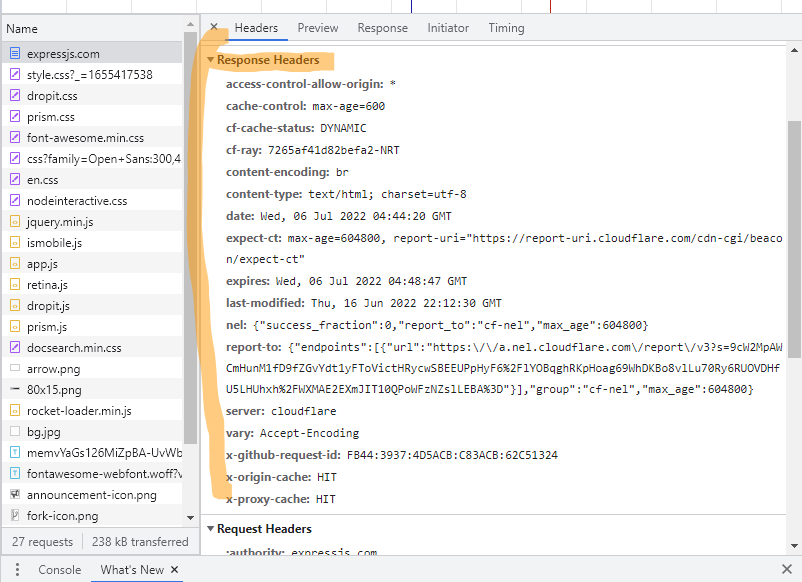
- 웹서버가 웹브라우저한테 데이터를 보낸다. 그 때 웹서버 자신은 잘 보이지 않는 정보까지 같이 보낸다.
- 'Content-Encoding: gzip'이라고 되어 있는 부분은 '웹서버가 gzip 방식으로 압축해서 보냈다'는 것을 의미한다. 그러면 웹브라우저는 이런 정보를 참조해서 gzip이라고 하는 방식으로 웹서버가 보내준 html 같은 정보를 압축을 푼 다음에 그것을 처리한다.
- Content-type은 '응답한 정보가 html이다. 그리고 utf-8 방식으로 인코딩이 되었다.' 이런 정보를 보내주면 웹브라우저는 자기가 받은 정보가 html이란 것을 알고 html의 형식에 맞게 웹 페이지 화면에 표시를 할 수 있게 된다.
[style.css]

- css를 클릭하면 content-type이 text/css인 것을 알 수 있다.
[bp.jpg]

- jpg 같은 경우에는 응답할 때 content-type이 image/jpeg라는 것을 알 수 있다.
- 만약에 이렇게 제대로 안 되어 있으면 우리가 이미지의 주소로 접속했을 때 다운로드가 되는 등의 문제들이 생길 수 있다.
웹브라우저와 웹서버 사이에는 http라고 하는 통신 방법을 통해서 서로 정보를 주고받는데, 그 통신 방법의 핵심은 리퀘스트 헤더와 리스폰드 헤더와 같은 웹브라우저와 웹서버가 주고받는 풍부한 데이터들이 있기 때문에 우리가 웹 애플리케이션을 잘 구동할 수 있는 것이다.
'웹서버에서 제공하는 프로토콜의 헤더에 어떤 정보가 어떻게 들어있기 때문에 내 웹브라우저가 이렇게 반응하는 것이다'라는 것까지 알게 된다면, 문제가 발생할 때 그 문제를 훨씬 더 짧은 시간에 훨씬 더 정확하게 해결할 수 있게 된다.
섹션 1.cookie
2 : counter

require('express')를 통해서 익스프레스를 가져오고, app 객체를 만든다.
app.listen(3003, ~)를 해서 3003번 포트를 가져온다.
쿠키를 구현하기 위해서는 쿠키 기능을 제공하는 모듈을 깔아야한다. -> expressjs.com의 API reference에서 찾아보기

var cookieParser = require('cookie-parser')
를 써서 모듈을 변수에 담는다.
express에서 app.use를 통해서 cookie-parser라는 것을 등록시킨다.
웹브라우저 웹서버에서 웹브라우저에 응답할 때 count라고 하는 쿠키 값을 세팅해서 그걸 웹브라우저에게 보낸다.
->응답할 때 보내기 때문에 response임

set-cookie에는 웹브라우저가 저 내용을 받아서 count=1이라고 저장했다는 내용이 들어가 있다.
localhost:3003으로 접속하게 되면 웹브라우저는 이 쿠키값 카운트 1을 전송한다.

숫자를 1씩 증가시키려면 var count = req.cookies.count;을 통해서 카운트라는 변수를 만들어서 이 카운트라는 변수에 쿠키 값을 담을 수 있게 한다.
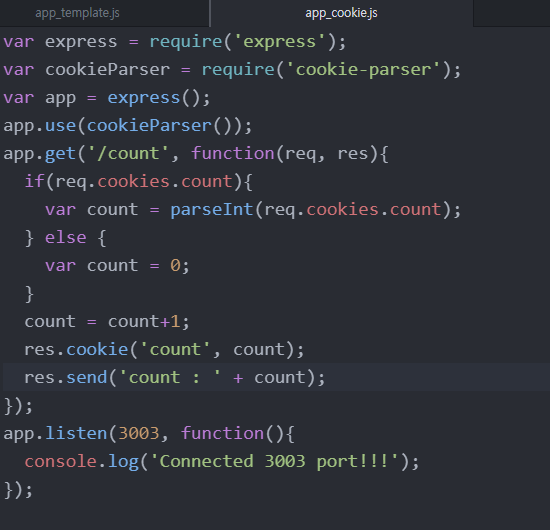
그런데 한 번도 쿠키를 구운 적이 있다면 웹브라우저는 어떤 값도 주지 않을 것이다. 그러니까 카운트 값이 없을 수도 있게끔 작성해야 한다. (자바스크립트에서는 값이 없으면 false라고 함)
parseInt를 통해서 문자를 숫자로 강제로 바꾸는 함수를 사용한다.
3 : shopping cart 1
애플리케이션을 만들 때 출발은 url이다. url을 따라서 적당한 컨트롤러를 실행시킬 수 있어야 하기 때문이다.
따라서 라우트를 먼저 설계할 필요하 있어야 한다.
products라고 하는 url로 접근하면 제품 목록이 나온다.

데이터를 꼭 가지고 있어야 되기 때문에 데이터베이스 대신에 배열을 만듦.
-> var products = {};
객체를 데이터베이스 대용으로 한다.
for(in)문을 이용해서 객체에 있는 값들을 하나 하나 순회해서 그 값을 꺼낸다.
-> for(var property in 객체) {}
중괄호가 실행될 때마다 네임의 값으로 그 객체의 프로퍼티 명의 name의 값을 할당되는 자바스크립트의 반복문임.
'products[name].title'를 통해서 title 객체에 있는 값들을 가져올 수 있음.
${products[name].title}로 작성해야 변수로 인식된다.
글 목록으로 하기 위해 <li>를 붙임.
클릭하면 링크로 만들기 위해 <a>태그로 감싸준다.

4 : shopping cart 2

상품1을 클릭하면 cart1로 이동하고, 상품2를 클릭하면 cart2로 이동하도록 만들었다. 그렇기 때문에 이동했을 때의 cart1과 cart2을 구현해야 한다.

장바구니 담았을 때 사용자가 담은 장바구니를 어떤 형식의 데이터로 저장해서 사용자의 웹브라우저에다가 심어놓을 것인지를 알아야 한다. 카트라고 하는 데이터를 사용자의 컴퓨터에 어떤 형식으로 저장할 것인지를 보면, cart1으로 접속하면 사용자의 브라우저에 저장하게 함.
객체를 사용자의 컴퓨터에 심기 위해서는 리스폰스 쿠키에다가 제품의 id 값에 해당되는 카운트 값을 저장해야 함.
cart에 값이 없다는 건 처음 실행시켰다는 것을 의미한다. 실행되면서 최초의 객체가 쿠키의 값으로 세팅된다. 그렇게 사용자의 브라우저에 쿠키값이 cart란 이름으로 심어지면 사용자가 이 페이지로 접근했을 때 그 값을 그대로 사용해서 cart를 얻을 수 있게 된다.
parseInt를 이용해서 cart값을 parseInt 안에서 숫자로 만든다.
cart에 id 값이 존재하지 않는 경우가 있지 때문에 if문에 !을 넣어서 부정의 의미를 만들어준다.

객체를 쿠키를 통해서 응답해서 사용자의 브라우저에 굽게 된다. 쿠키가 잘 구워지는지 확인하기 위해서 send 값으로 cart를 넣어서 이 cart 객체에 담겨 있는 값들이 잘 세팅되어서 브라우저에 전송되는지 물을 수 있다.
-> res.send(cart);
5 : shopping cart 3
cart 페이지를 꾸미기 위한 코드 작성
if문과 !를 사용해서 cart가 비어있으면 Empty를 출력하고 그렇지 않으면 값을 분석하도록 한다.

제품의 id 값을 통해서 product에 접근할 수 있게 된다.
언제든지 이전 페이지로 돌아갈 수 있도록 하기 위해서 <a>태그를 사용하여 Products List라는 링크를 만든다.
현재 페이지가 무엇인지 나타내기 위하여 <h1>태그를 사용한다.

6 : cookie & security
쿠키는 보안쪽으로 취약하다.
서버 웹브라우저가 서로 쿠키를 주고받는 과정에서 누군가가 중간에서 쿠키 값을 볼 수 있다. 그런데 만약 로그인과 관련된 쿠키라든지 중요한 사안이 들어있는 쿠키가 있을 수 있다. 그런 것이 누군가에 의해 도청 당한다면 심각한 보안상 문제가 발생하게 된다. 특히나 쿠키 같은 경우에는 전송하는 과정에서 유출될 수 있지만 컴퓨터에 있기 때문에 누군가에 의해서 쿠키 값이 읽힌다면 보안에 심각한 위협이 될 수 있다.
암호화된 정보가 서버와 클라이언트 사이를 왔다갔다 하기 때문에 안전해진다.
또 쿠키값 자체를 암호화할 수 있다. 쿠키를 세팅하는 cookie-parser라는 부분에다가 인자를 아무값이나 준다. 그리고 아무렇게나 입력한 값이 키 값이 된다.

서버에서 브라우저로 쿠키를 구울 때, 암호화된 정보를 굽는다는 뜻이다. 그러면 브라우저는 암호화된 상태로 저장했다가 서버에 요청(request)할 때, 암호화된 정보를 그대로 보내주면 우리는 이 키 값을 이용해서 암호화된 정보를 해석하면 원래 값으로 다시 바꿀 수 있다. 그리고 그런 역할을 하는 것을 키라고 부른다.
count 기능을 암호화를 적용한다.

이렇게 바꾸면 이 사용자의 쿠키값이 암호화가 되어있지 않은 상태인데, 암호화된 쿠키가 전달됐을 때 쌓인 쿠키를 통해서 암호가 해독된 키 값으로 해독시킨 정보를 가져올 수 있게 된다.
쿠키를 처리하는 부분을 다 signedCookie로 바꾼다.

signed를 이용해서 암호화해서 쿠키를 저장한다.
또, 쿠키를 이용해서 사용자를 로그인시키는 것도 가능하다. 즉, 사용자가 로그인에 성공하면 그 아이디와 비밀번호를 이 쿠키로 저장하게 된다. 그럼 그 다음에 접속할 때 쿠키 값을 보고 그 아이디와 비밀번호에 해당되는 사용자가 있으면 '로그인 되었다'고 간주할 수 있다. 그러나 이 경우에는 http로 배달 사고를 방지한다고 하더라도 어떤 문제가 일어날지 예측하기 힘들다. 그렇기 때문에 아이디, 비밀번호와 같은 중요한 정보는 절대로 쿠키에 저장하지 않는다.
섹션 2.Session
1 : intro
우리가 배울 session은 이전에 배운 쿠키를 개선한 방식이다.

설치되어 있는 컴퓨터가 있고, 구름이 서버라고 가정하면, 웹브라우저가 서버에 접속하면 서버는 웹브라우저에게 응답을 하고 쿠키로 모든 데이터를 저장하게 된다.
쿠키로 로그인과 관련된 중요한 정보를 저장하게 되면, 보안상 이슈가 발생할 수 있다. 즉, 사용자의 컴퓨터와 서버가 서로 통신하는 과정에서 중요한 정보과 왔다갔다 한다는 것은 누군가가 중간에서 컴퓨터에 저장되어 있는 쿠키를 가로챌 수 있기 때문에 굉장히 부담스러운 일이다.
따라서 서버 쪽에서 데이터를 저장할 수 있는 공간을 잘 조합해서 세션을 만들어서 사용한다면 훨씬 더 좋은 접근을 만들 수 있다. 쿠키 방식과는 다르게 오직 사용자의 식별자 id값만을 저장한다. 실제 데이터는 서버에 저장이 되고, 사용자의 컴퓨터에는 그 사용자를 식별할 수 있는 식별자만 저장된다. 그리고 사용자가 접속하면 데이터에서 식별자에 해당하는 실제 데이터를 읽어와서 사용할 수 있게끔 만들어준다.
2 : counter 1
session을 이용할 경우, responde headers 즉 응답한 내용을 보면, set-cookie에 count값이 없다. 그리고 connect.sid가 되게 길다. 즉, 웹서버는 웹브라우저에다가 구체적인 값을 저장하는 대신에 웹브라우저에게 고유한 값을 전달한다. 이 값은 중복될 일이 없고, 이 값을 웹서버가 웹브라우저에게 준다. 그럼 웹브라우저는 다음부터 웹서버에 접속할 때는 이 값을 웹서버로 계속해서 전달한다. 그러면 서버 입장에서는 이런 형식의 이런 값을 가지고 있는 요청들을 같은 사용자의 접근이라고 생각하게 된다.

세션 방식을 이용하게 되면, 접속할 때는 connect.sid값만 전달하게 된다. 그러면 웹서버는 그 값을 가지고 그 값에 해당되는 카운트 값을 읽어서 서버 쪽에 저장하고, 그 값에 1을 더한 결과를 응답한다.
세션과 쿠키 방식은 둘 다 쿠키를 이용한다. 하지만, 쿠키 방식은 사용자의 컴퓨터에 쿠 키를 이용해서 카운트 값 자체를 직접 저장한다. 세션 방식은 카운트 값을 저장하는 것이 아니라, 사용자의 식별자만 저장했다가 응답할 때는 그 식별자에 해당되는 데이터를 서버 안에 저장되어 있는 데이터를 가지고 와서 응답한다. 이러면 사용자의 컴퓨터 자체의 쿠키값이 저장되지 않기 때문에 훨씬 더 안전하다. 데이터를 사용자의 컴퓨터가 아니라 서버에 저장하고 있기 때문에 많은 데이터도 저장할 수 있다.
3 : counter 2
세션 기능을 우리의 익스프레스에 추가시키기 위해서 npm install express-session --save 명령어를 입력한다.
app_session.js파일을 새로 만든다.

resource의 cookies를 보면 connect.sid가 있다. 거기에 session id값과 카운트 1이라는 값을 연결시켜서 이 값으로 접근하는 사용자는 카운트1이라는 값을 가려갈 수 있게 하는 것이다.
req.session.count을 이용해서 req.session.count에 담겨 있는 값을 출력한다.
사용자의 정보를 req.session.count에 저장하고 사용자에게만 이 값을 전달한다.

connect.sid가 별도의 데이터를 서버에 저장해서 유지할 수 있다.
사용자의 데이터는 서버의 메모리에 저장한다.
4 : login 1
로그인 기능을 session을 이용해서 만드는 법 배우기
로그인을 하면 Hello login이라는 정보가 나오도록 수정하기

로그인 창을 만들기 위해 <form>태그 사용하기
username을 입력할 창 만들기

5 : login 2
아이디와 비밀번호를 입력하고 전송한다.
웅답헤드의 send를 이용해서 사용자가 전송한 정보가 post 방식으로 오면 body로 받아야 한다.
username을 화면에 출력하기 위해서 리로드를 하면 에러가 난다. 그 이유는, 기본적으로 익스프레스는 post 방식으로 전송된 데이터를 처리해 주지 않기 때문이다. 따라서 그걸 해주는 모듈을 설치해야 한다. 그때 사용하는 모듈이 body-parser이다.

<h1>태그를 이용해서 화면에 login 글씨를 나타낸다.
복잡성을 낮추기 위해서 사용자가 아니라 user라고 하는 객체를 만든다.
-> var user = {
username:'egoing',
password:'111'
};
로그인창에 입력한 아이디와 패스워드가 저장한 내용과 일치하면 Hello master를 출력하고, 아니라면 Who are you?를 출력하게끔 작성한다.
또 로그인에 실패하면, 다시 로그인 페이지로 갈 수 있도록 링크를 주기 위해 <a> 태그를 사용한다.
또 로그인에 성공하면 사용자를 웰컴 페이지로 보내기 위해서 redirect를 사용한다.
